
Java8-Stream流讲解

Java8-Stream流讲解
yngcy什么是 Stream
Stream 简介
在处理集合数据时,常常需要对其进行各种操作,例如过滤、映射、规约等。而 Java 8 中引入的 Stream 流为我们提供一种更加简洁和灵活的方式来处理数据。
Stream 特性
- stream 不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果。
- stream 不会改变数据源,通常情况下会产生一个新的集合或一个值。
- stream 具有延迟执行特性,只有调用终端操作时,中间操作才会执行。
如何使用 Stream
简单来讲,Stream 流操作分为以下 3 种:
- 创建 Stream 流
- Stream 流中间处理
- 终止 Stream 流
创建 Stream 流
从 Collection 创建流
1 | public class CollectionToStreamExample { |
上述代码中,首先创建了一个包含字符串元素的 List 集合,并使用 Arrays.asList 方法将元素添加到集合中。这里集合包含了“cat“, “dog”, “tiger”, “fish“和“bird”。
接下来调用 animals.stream 方法将 List 转化为一个流对象。这里使用了流的中间操作方法 filter 来过滤出长度小于等于 3 的元素。filter 方法接收一个 Lambda 表达式,对每个流元素进行判断,将符合条件的元素留下。
然后调用 map 方法将流中的元素转化为大写字母形式。这里使用了方法引用 String::toUpperCase 来指定转化的逻辑。
最后,代码调用 forEach 方法来遍历流中的元素并打印出来。这里使用了方法引用 System.out::println 来指定打印的逻辑。
从数组中创建流
1 | public class ArrayToStreamExample { |
上述代码中,首先创建了一个数组,再使用 Arrays.stream 将数组转为一个流对象。接着使用 filter 方法过滤掉小于等于 3 的元素,再用 map 方法将元素变成原来的 10 倍。最后调用 forEach 遍历执行输出。
调用 Stream 的静态方法
Stream.of - 指定具体元素的流
1 | Stream<String> stream = Stream.of("cat", "dog", "fish"); |
Stream.iterate - 迭代生成元素的流
1 | Stream<Integer> stream = Stream.iterate(1, (x) -> x * 2); |
Stream.generate - 指定 Supplier 生成元素的流
1 | Stream<Double> stream = Stream.generate(Math::random) |
* Stream.Builder 创建流
1 | public class StreamBuilderExample { |
Stream.Bulider 帮助我们逐步构建一个流,通过 add 方法添加元素,然后使用 build 方法创建流。
应用场景
因为其允许在构建流的过程中动态地创建流,所以这种构建方式适合元素不确定或者需要动态处理地场景。
*从文件创建流
1 | public class FileToStreamExample { |
一般处理文件的方式使用 BufferedReader 等类逐行读取,但是使用 Stream 流可以很方便的读取文件。例如上述代码中使用 Files.lines 方法,将文件的每一行转换成流,然后再对其进行一系列操作。
使用 Stream 流可以有效的使代码更加简洁,可读性强。此外 Stream 还提供了并行处理的能力,通过多线程进行并行计算,提高程序运行效率。使用 Stream 可以更加有效的管理内存,降低内存占用,提高效率。最后,Stream 的操作都是基于函数式编程的思想,通过方法引用或是 Lambda 表达式进行各种操作,可维护性和可扩展性好。
关于 Stream 可以更加有效地管理内存资源的原因如下:
- 惰性计算:Stream 是基于惰性计算的,只有当需要结果的时候才会执行。这意味着在处理大量数据时,可以按需计算,而不是一次性加载完所有的数据到内存中。这有效的节省了内存资源。
- 内部迭代:Stream 提供了一种内部迭代的方式,同时 Stream 内部已经优化了迭代的方式,可以更高效地利用内存资源。
- 并行处理:Stream 因为支持并行处理,将数据划分多个子任务并行处理,然后合并,充分利用了多核 CPU 的性能。同时 Stream 优化了任务的分配和调度,以最大限度地利用内存资源。
Stream 流中间处理
在介绍具体的处理方法前,需要再明确 Stream 的一个特性——延迟性。当多个中间操作按顺序进行时,除非流终止,否则中间操作不会执行。
这样做的原因是提高性能,减少了对每个元素的实际操作数。
例如下面代码:
1 | Stream.of("a1", "a2", "b1", "c1") |
输出结果如下:
1 | map: a1 |
由于数据流的链式调用是垂直执行的,map 在这里只执行 3 次。相当于水平执行来说,执行次数减少了,不是把所有的元素都进行 map 转换,从而提高了性能。
**所以,中间操作的顺序要考虑仔细!**例如,先 map 再 filter 和先 filter 再 map 的操作次数可能相差很大!
也有一些流处理方法是水平执行的,例如 sorted。当然,上面说到的优化技巧也同样适用于水平执行的流处理方法(先 filter 后再 sorted)。
筛选与切片
| API | 功能说明 |
|---|---|
| filter(Predicate p) | 接收 Lambda,从流中过滤不满足条件的元素 |
| distinct() | 去重筛选 |
| limit(long maxSize) | 截断流,使其元素不超过给定数量 |
| skip(long n) | 跳过元素,返回一个跳过前 n 个元素的流。若流中的元素不足 n 个,则返回一个空流。即与 limit(n) 互补 |
映射
| API | 功能说明 |
|---|---|
| map(Function f) | 接收一个函数作为参数,该函数会被作用在每个元素上,一对一逻辑,返回新的 Stream |
| mapToDOuble(ToDoubleFunction f) | 接收一个函数作为参数,该函数会被作用在每个元素上,产生一个新的 DoubleStream |
| mapToInt(ToIntFunction f) | 接收一个函数作为参数,该函数会被作用在每个元素上,产生一个新的 IntStream |
| mapToLong(ToLongFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 LongStream |
| flatMap(Function f) | 接收一个函数作为参数,将流中的每个值转换成一个流,一对多逻辑,然后连接它们成一个新的 Stream |
map 与 flatMap 方法
map 与 flatMap 都是用于转换元素,区别在于:
map必须是一对一的flatMap可以是一对多的
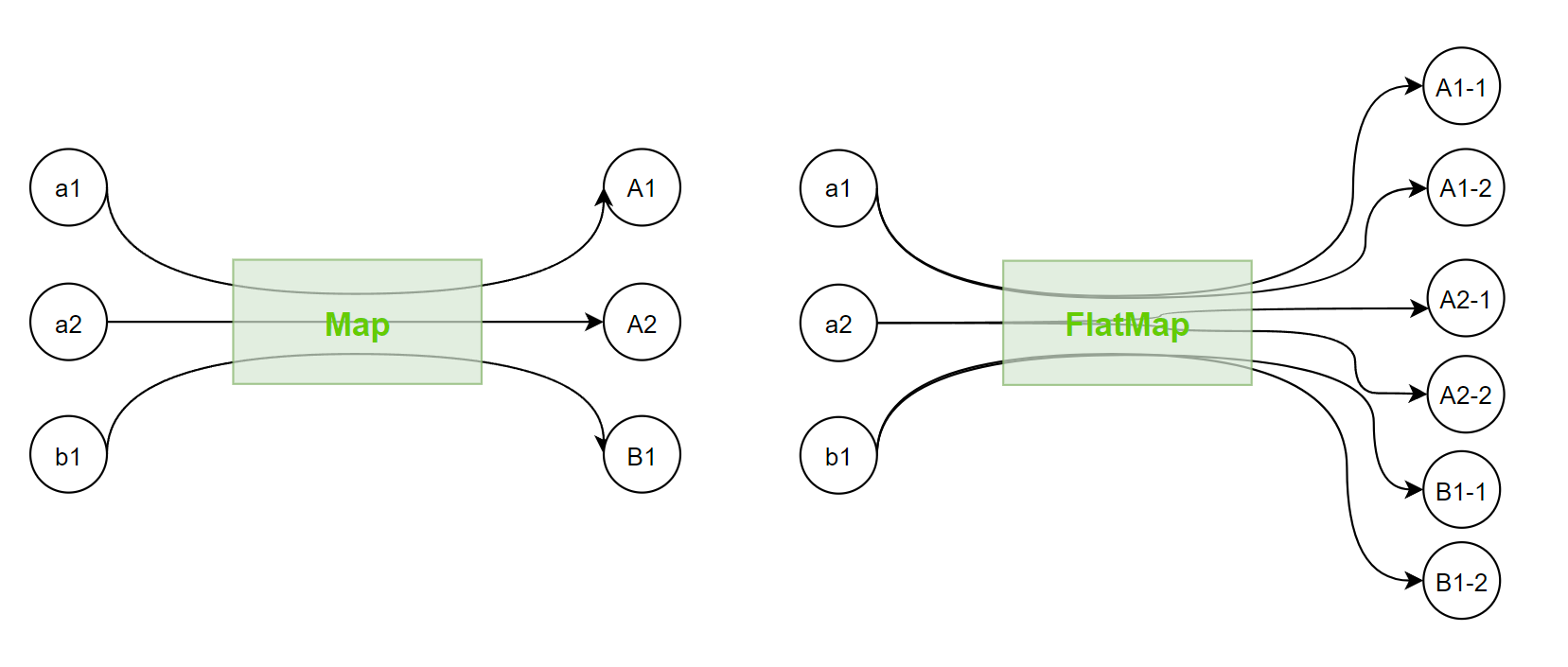
map 接口定义如下:
1 | <R> Stream<R> map(Function<? super T, ? extends R> mapper); |
其参数是接收一个 Function,接收一个 T 型参数,返回一个 R 型参数,例如在实际业务中,将 DAO 类型转为对应的 DTO 类型。另外,当 T 和 R 相同时,也就和 peek 没什么区别了。
flatMap 适用于将结构降维,即扁平化。一般有以下 3 种情况:
Stream<String[]>Stream<Set<String>>Stream<List<String>>
上述结构可通过 flatMap 方法,将结果转为 Stream<String>,方便后续操作。
另外,flatMap 可以和 Optional 类结合使用,减少繁琐的 null 检查。
假设有一个 List<Optional<String>>,我们想要将其中不为空的 Optional 对象中的字符串转换为大写:
1 | List<Optional<String>> list = Arrays.asList(Optional.of("hello"), Optional.empty(), Optional.of("world")); |
如果我们使用map方法对Optional对象进行映射,那么就需要进行繁琐的 null 检查,代码会变得更加复杂。
当我们使用
map方法对一个Optional对象进行映射时,如果Optional对象中的值为空,那么映射的结果也会是一个空的Optional对象。这就导致了在后续的操作中需要进行繁琐的 null 检查。
排序
| API | 功能说明 |
|---|---|
| sorted() | 按照自然序排序(升序) |
| sorted(Comparator com) | 按照给定的比较器排序 |
合并
| API | 功能说明 |
|---|---|
| concat() | 将两个流的数据合并成一个新的流 |
处理
| API | 功能说明 |
|---|---|
| peek() | 对 Stream 流中的每个元素进行处理,返回处理后的 Stream |
终止 Stream 流
通过终止管道后,Stream 流会结束,一般在返回时会做一些操作,返回处理后的结果。注意,流结束时候一般不能再次使用(可以使用 Supplier 包装流,通过 get 方法构建新的流来实现流的复用)。
匹配/查找
| API | 功能说明 |
|---|---|
| allMatch(Predicate p) | 检查是否匹配所有元素,返回 boolean |
| anyMatch(Predicate P) | 检查是否至少匹配一个元素,返回 boolean |
| noneMatch(Predicate p) | 检查时候没有匹配所有元素,返回 boolean |
| findFirst() | 返回第一个符合条件的元素 |
| findAny() | 返回当前流中符合条件的任意元素(串行流与 findFirst 相同,并行流时更加高效) |
| count() | 返回流中的元素总数 |
| max(Comparator c) | 返回流中的最大值 |
| min(Comparator c) | 返回流中的最小值 |
| forEach(Consumer c) | 无返回值,对元素进行逐个遍历,执行给定的处理逻辑 |
peek 与 forEach
peek 和 forEach 都可以对每个元素进行逐个处理。
但是 peek 属于中间方法,peek 操作完之后还是一个 Stream 流,而 forEach 属于终止方法,执行之后 Stream 流就没有了。根据前面提到的,如果想要看到处理结果,要么使用 peek + 一个终止方法或者使用 forEach 方法。
归约
| API | 功能说明 |
|---|---|
| reduce(BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值,返回 Optional |
| reduce(T iden, BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值,返回 T |
| reduce(T iden, BiFunction acc, BinaryOperator b) | 规定累加器,将多个结果合并为一个结果。 |
例如,计算元素的和:
1 | List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5); |
第一种方法接收 BinaryOperator 参数,这个参数用于将 Stream 中的元素合并为一个结果,在上述代码中,使用 Lambda 表达式将两个元素相加,最后返回累计和。
如果我们不想要得到 Optional 对象,可以使用如下方式:
1 | List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5); |
第二种方法接收一个初始值和一个 BinaryOperator 参数。使用初始值 0 即可避免返回 Optional 对象,这个初始值的类型与元素类型要保持一致。
此外还可以规定累加器方法,例如,求学生的成绩总和:
1 | Integer socreSum = students |
不过这种方法一般结合并行流使用。
1 | Integer socreSum = students |
收集
| API | 功能描述 |
|---|---|
| collect(Collector c) | 将流转换为其他形式(List、Map 等)。接收一个 Collector 接口实现,用于给 Stream 中给的元素做汇总的方法 |
| toArray() | 将 Stream 流转为数组 |
collection
当我们在使用 Stream 时,通常为了获取其结果是 List / Map 类型时,就需要用到 collection。
collect 方法用于将流中的元素放到一个集合。
例如下面代码,将字符串列表元素放入一个新的列表中:
1 | public class StreamCollectExample { |
输出结果如下:
1 | [banana, orange] |
collect 还提供了其他收集器,如 toMap()、toSet() 等。
还有 Collectors.groupingBy() 等用来分组:
1 | public static void main(String[] args) { |
输出结果如下:
1 | {a=[apple], b=[banana], o=[orange], p=[pear], g=[grape]} |
可以看到,输出结果中按照首字母进行分组。groupingBy 方法还支持多条件分组,根据实际情况选择。
还有 counting() 等用来进行归约操作,实际 JDK 为了方便提供了归约逻辑的封装,如 count()。
1 | public class StreamMaxByExample { |
可以看到,使用 collect() 方法和 max() 方法都可以找到该流中的最大值,但是使用 max() 方法可以更加简化代码,同时也更加直观易懂。因此,在实际开发中,我们可以根据实际需求选择合适的方法来实现相应的功能。
并行 Stream
Stream API 还为我们提供了并行处理 Stream 的方式,通过 parallelStream 方法或者 parallel 方法创建并行 Stream 对象。
并行流底层使用的是 ForkJoinPool,线程池的大小最多为 5 个,具体取决于 CPU 的核心数。ForkJoin 框架采用分治策略,你还可以自定义线程池,不过一般情况下默认的也够用了。
并行流对含有大量元素的数据时性能提升很大,但同时要注意,在使用并行时会有额外的组合操作,这部分也会花费一定的时间。
使用细节及注意事项
- 必须在多核 CPU 的主机上使用;
- 当数据量不大时,串行 Stream 和并行 Stream 性能相差不大,无需使用并行 Stream;
- 因为并行计算依赖 CPU,所以 CPU 密集型计算适合并行 Stream,而 IO 密集型使用时因多个线程频繁切换反而会更慢;
- 当需要使用 collect 合并的时候,合并时间可能会很长,不适合使用并行 Stream;
- 例如 limit、findFirst 等依赖元素顺序的操作不适合使用并行 Stream;
- 类似于多线程场景,可能会产生死锁问题,所以要保证线程安全。
总之,在使用并行 Stream 之前最好先实践一下是否能提高性能。
参考
【1】8000字长文让你彻底了解 Java 8 的 Lambda、函数式接口、Stream 用法和原理 - 掘金 (juejin.cn)













