
MySQL8.0的窗口函数

MySQL8.0的窗口函数
yngcyMySQL中的窗口函数
前言
最近在练习 sql 时碰到了一类题:查询表中的前 n 项。直接想到的是用 order 排序然后使用 limit 获取前 n 项。例如,获取每天刷题通过数最多的前三名用户id和刷题数,DDL 如下:
1 | drop table if exists questions_pass_record; |
编写查询 SQL 如下:
1 | SELECT `date`, user_id, pass_count |
执行结果如下:
| date | user_id | pass_count |
|---|---|---|
| 2018-08-05 | 105 | 60 |
| 2020-03-01 | 102 | 15 |
| 2021-04-09 | 202 | 11 |
显然,这不是我们想要的结果。那么该如何解决呢?在一些 DBMS(如 PostgreSQL、Oracle、Microsoft SQL Server、IBM Db2 等),已经考虑到了这种情况,提供了窗口函数 帮助我们查询。
什么是窗口函数
MySQL 从 8.0 开始支持窗口函数,窗口函数一种用于在查询结果中执行聚合计算或排序操作的特殊函数。它们能够对查询结果集中的行进行分组、排序和排名,而无需使用 GROUP BY 子句。
这个功能在大多商业数据库中早已支持,也叫分析函数。
语法详解
窗口函数的一般语法如下:
1 | <窗口函数>([参数]) OVER ([PARTITION BY <分组列>] |
窗口函数(window_function_name)
window_function_name 窗口函数可以是聚合函数和或非聚合函数,窗口函数可以和聚合函数一起使用,也可以单独使用。MySQL 8.0 支持以下几类窗口函数:
- 序号函数:用于为窗口内的每一行生成一个序号,如
ROW_NUMBER()、RANK()、DENSE_RANK()等; - 分布函数:用于计算窗口内的每一行在整个分区中的相对位置,如
PERCENT_RANK()、CUME_DIST()等; - 前后函数:用于获取窗口内当前行的前后某一行的值,如
LAG()、LEAD()等; - 头尾函数:用于获取窗口内的第一行或最后一行的值,如
PIRST_VALUE()、LAST_VALUE等; - 聚合函数:用于计算窗口内的某个字段的聚合值,如
SUM()、AVG()、MIN()、MAX()等;
根据函数的定义,有些要设置参数,下面会再详细介绍。
OVER
OVER 关键词用来标识是否使用窗口函数。OVER 关键字后面可以跟随 (窗口规范) 或窗口名称。
PARTITION BY
PARTITION BY 子句用来查询结果划分为不同的分区,窗口函数在每个分区上分别执行。
这种分组类似于普通的聚合函数中使用 GROUP BY 子句,但不同的是,窗口函数不会导致结果集的行数减少。相反,它会为每个输入行计算一个单独的结果,而不会对结果集进行聚合。
通过使用PARTITION BY,可以轻松在窗口函数中进行分组计算,并对每个分组应用相应的窗口函数逻辑。这提供了对数据的灵活控制和更精确的计算结果。
ORDER BY
ORDER BY 子句用来对每个分区内查询结果进行排序,窗口函数将按照排序后的结果再进行计算。
窗口帧
窗口帧(Window Frame)是窗口函数中的一个概念,用于定义在每个分区中要处理的行的范围。它指定了相对于当前行的起始行和结束行的位置。
在窗口函数中,可以使用窗口帧来控制窗口函数计算的行的子集。窗口帧通过指定边界来定义要包含在窗口中的行。
有几种类型的窗口帧:
- 行范围帧(ROW):
ROWS BETWEEN <start> AND <end>。在窗口中指定一定数量的行,相对于当前行而言。可以使用ROWS关键字来指定。例如,ROWS 3 PRECEDING表示包括当前行及前面的 3 行。 - 范围帧(RANGE):
RANGE BETWEEN <start> AND <end>。在窗口中指定基于值的范围,而不是具体的行数。使用范围帧时,窗口函数必须有一个排序规则,并且基于排序规则确定范围。例如,RANGE BETWEEN 100 PRECEDING AND 100 FOLLOWING表示基于值范围的窗口,包括相对于当前行的前 100 行和后 100 行。 - 当前行帧(CURRENT ROW):表示只包括当前行自身。
- UNBOUNDED PRECEDING:到分区的第一行为止。
- UNBOUNDED FOLLOWING:到分区的最后一行为止。
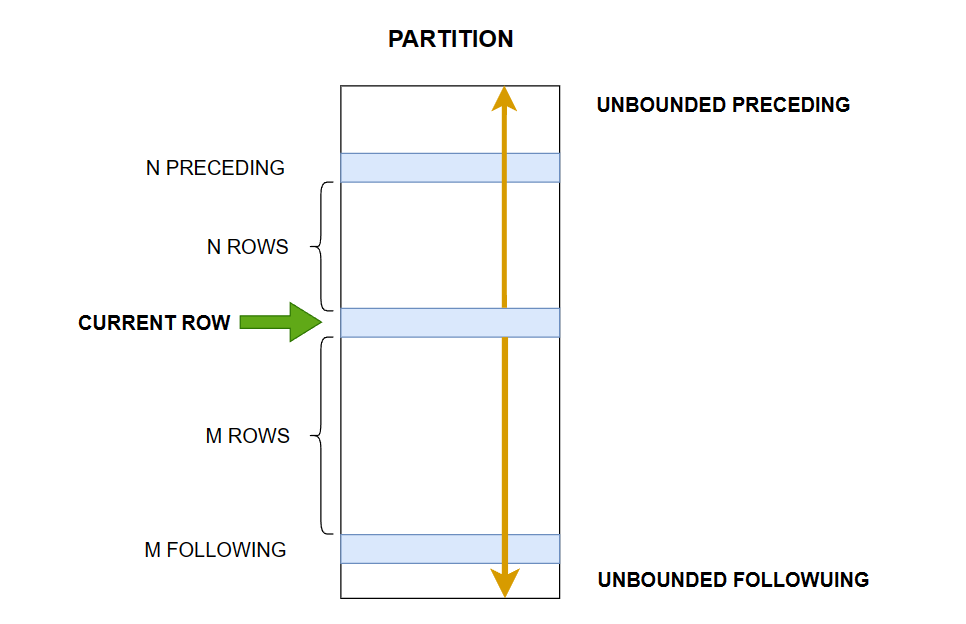
如果没有指定窗口帧,默认为 RANGE BETWEEN UNBOUNED PRECEDING AND CURRENT ROW,即分区开始到当前行。
常用窗口函数
ROW_NUMBER()
用于生成每行的唯一编号的函数。它通常在数据库查询中使用,特别是在需要基于行顺序进行一些计算或排名的场景中。
语法:
1 | ROW_NUMBER() OVER ( |
示例:
1 | SELECT user_id, pass_count, date, ROW_NUMBER() OVER(PARTITION BY date ORDER BY pass_count DESC) rk |
运行结果:
| user_id | pass_count | date | rk |
|---|---|---|---|
| 105 | 60 | 2018-08-15 | 1 |
| 104 | 20 | 2018-08-15 | 2 |
| 304 | 10 | 2018-08-15 | 3 |
| 102 | 15 | 2020-03-01 | 1 |
| 101 | 2 | 2020-03-01 | 2 |
| 202 | 11 | 2021-04-09 | 1 |
| 102 | 9 | 2021-04-09 | 2 |
| 104 | 3 | 2021-04-09 | 3 |
在上述示例中,我们使用 ROW_NUMBER() 函数来为每个提交记录按照日期分页,然后再根据 pass_count 降序排序,并为每条记录分配一个 rk 排名。
RANK()
RANK() 函数用于生成每行的排名。它考虑了并列名次的情况,并会跳过并列名次之后的名次。这意味着如果有多个行具有相同的排名,它们将获得相同的排名,并且下一个排名将会跳过。
语法:
1 | RANK() OVER ( |
示例:
1 | INSERT INTO questions_pass_record VALUES(666, 'sql', 'pc', 20, '2018-08-15'); |
运行结果:
| user_id | pass_count | date | rk |
|---|---|---|---|
| 105 | 60 | 2018-08-15 | 1 |
| 104 | 20 | 2018-08-15 | 2 |
| 666 | 20 | 2018-08-15 | 2 |
| 304 | 10 | 2018-08-15 | 4 |
| 102 | 15 | 2020-03-01 | 1 |
| 101 | 2 | 2020-03-01 | 2 |
| 202 | 11 | 2021-04-09 | 1 |
| 102 | 9 | 2021-04-09 | 2 |
| 104 | 3 | 2021-04-09 | 3 |
在上述示例中,可以看到,user_id=666 与 user_id=104 的排名重合,因此它俩的排名是一样的,随后下一个又跳过了 3。
DENSE_RANK()
DENSE_RANK() 函数用于生成每行的密集排名。与RANK() 函数不同,DENSE_RANK() 函数在并列名次的情况下不会跳过下一个排名。这意味着如果有多个行具有相同的排序值,它们将获得相同的排名,并且下一个排名不会被跳过。
语法:
1 | DENSE_RANK() OVER ( |
示例:
1 | SELECT user_id, pass_count, date, DENSE_RANK() OVER(PARTITION BY date ORDER BY pass_count DESC) rk |
运行结果:
| user_id | pass_count | date | rk |
|---|---|---|---|
| 105 | 60 | 2018-08-15 | 1 |
| 104 | 20 | 2018-08-15 | 2 |
| 666 | 20 | 2018-08-15 | 2 |
| 304 | 10 | 2018-08-15 | 3 |
| 102 | 15 | 2020-03-01 | 1 |
| 101 | 2 | 2020-03-01 | 2 |
| 202 | 11 | 2021-04-09 | 1 |
| 102 | 9 | 2021-04-09 | 2 |
| 104 | 3 | 2021-04-09 | 3 |
在上述示例中,可以看到,在排名重合后,user_id=304 的排名为 3 而不是 4,排名序号没有跳过。
SUM()、AGV()、COUNT() 等聚合函数
它们的用法同一般的聚合函数一样,可以在指定的窗口中进行聚合计算。
示例:
1 | SELECT date, SUM(pass_count) OVER (PARTITION BY date) AS total_pass_count |
运行结果:
| date | total_pass_count |
|---|---|
| 2018-08-15 | 110 |
| 2018-08-15 | 110 |
| 2018-08-15 | 110 |
| 2018-08-15 | 110 |
| 2020-03-01 | 17 |
| 2020-03-01 | 17 |
| 2021-04-09 | 23 |
| 2021-04-09 | 23 |
| 2021-04-09 | 23 |
在上述示例中,查询了每天的提交通过总数,多条记录的重复说明了窗口函数是对每条记录获取到一个窗口(从分区第一行到当前行)再进行聚合计算,用 DISTINCT 关键字去重即可。
1 | SELECT |
LAG()/LEAD()
窗口函数 LAG() 和 LEAD() 是用于访问窗口中前一行或后一行的数据的函数。它们都需要指定一个参数,即偏移量,表示要获取的前一行或后一行的位置。
语法:
1 | LAG(expression [, offset [, default]]) |
参数说明:
expression:要访问的列或表达式。offset:可选的偏移量,表示要获取的前一行或后一行的位置。默认为1,表示获取前一行或后一行的数据。default:可选的默认值,当没有更多行可用时返回的默认值。如果未指定默认值,并且没有更多行可用,则返回NULL。
示例:
1 | SELECT |
运行结果:
| user_id | date | pass_count | lag_value | lead_value |
|---|---|---|---|---|
| 105 | 2018-08-15 | 60 | 20 | |
| 104 | 2018-08-15 | 20 | 60 | 10 |
| 304 | 2018-08-15 | 10 | 20 | 20 |
| 666 | 2018-08-15 | 20 | 10 | 2 |
| 101 | 2020-03-01 | 2 | 20 | 15 |
| 102 | 2020-03-01 | 15 | 2 | 9 |
| 102 | 2021-04-09 | 9 | 15 | 11 |
| 202 | 2021-04-09 | 11 | 9 | 3 |
| 104 | 2021-04-09 | 3 | 11 |
在上面的示例中,LAG(pass_count) 将返回当前行的前一行的 pass_count 值,LEAD(pass_count) 将返回当前行的后一行的 pass_count 值。
窗口名称
MySQL 8.0 中可以给窗口命名,然后在 OVER 子句中通过窗口名来引用。这样做的好处是减少重复代码,类似于 Java 中重复代码抽象出单独的方法。
示例:
1 | SELECT |
在上面的示例中,定义了名为 w 的窗口,然后在 OVER 子句中引用它。
另外,窗口之间可以互相引用,但是要避免循环引用。
案例分析
引用上面的表,下面具体来解决一些问题。
将提交记录按照提交数进行排名
1 | SELECT *, RANK() OVER(PARTITION BY date ORDER BY pass_count DESC) rk |
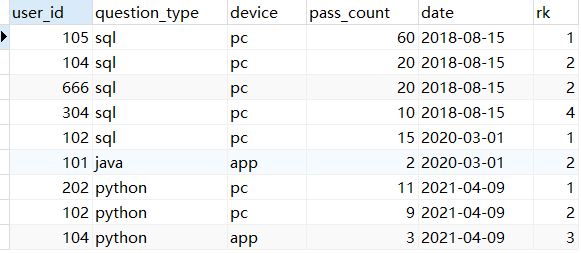
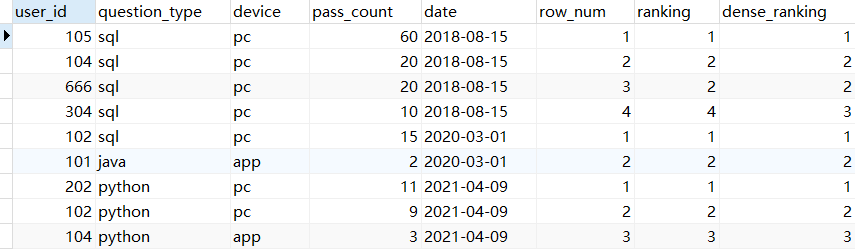
对比 ROW_NUMBER()、RANK()、DENSE_RANK() 的区别
1 | SELECT |
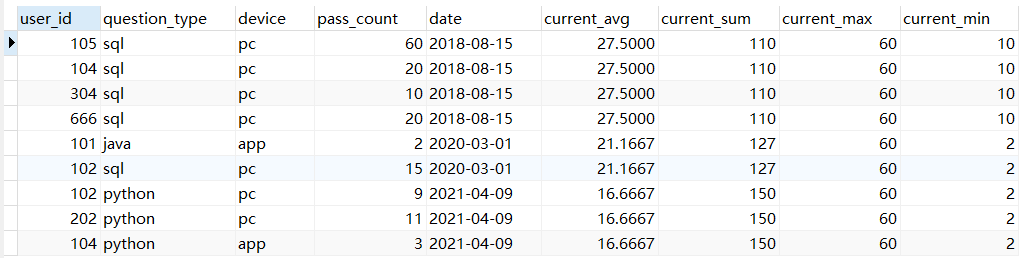
聚合窗口函数使用
1 | SELECT |
经典 TOP N 问题
所有提交记录取前 3 名:
1 | SELECT a.user_id, a.pass_count, a.date, a.ranking |
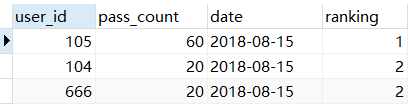
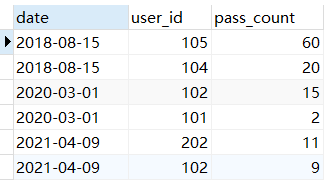
统计每天前 2 的用户:
1 | SELECT date, user_id, pass_count |
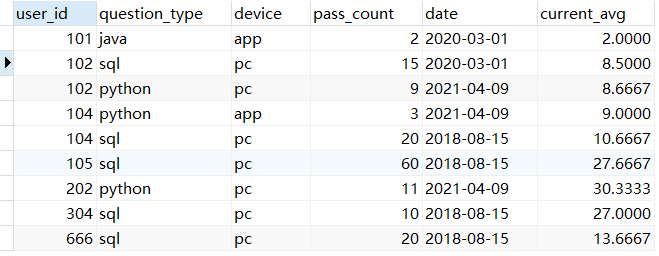
聚合滑动计算
1 | # 取当前行的前两行的平均 |
窗口函数的优缺点
优点:
- 灵活性高:窗口函数允许用过户在查询结果中自定义的排序,聚合和华东计算操作,使得用户能够更加灵活地处理和分析数据。
- 性能优化:窗口函数通常比使用常规的聚合函数和子查询更加高效,因为它们在 DBMS 中进行了优化,能够利用更高效的算法来执行计算。
- 可读性强:使用窗口函数可以使查询结果更加可读,因为进行和函数封装,并且使用别名来表示结果。
缺点:
- 语义不清晰:窗口函数的语法较为复杂,初学者可能比较难以理解。
- 限制条件:某些数据库可能对窗口函数的支持优先。例如 MySQL 8.0 才支持窗口函数,而 MySQL 5.7 不支持。
- 性能开销:虽然窗口可以在一般情况下可以提高查询性能,但在处理大量数据时,使用窗口函数可能还会导致额外的计算和内存开销。
窗口函数的性能取决于窗口类型、窗口大小、分区数量、排序代价等。因为窗口函数只需要一次扫描数据,所以对于大多数情况来说,其性能优于使用子查询或连接的方法。
当窗口函数同一些聚合函数使用时,性能就会下降。
可以采用如下优化方法:
- 选择合适的窗口函数,避免使用复杂或重复的窗口函数。
- 使用窗口别名来定义和引用窗口。
- 尽量减少分区和排序的代价,使用缩影和物化视图来加速分区和排序。
- 尽量减小窗口的大小,使用合适的窗口帧来限制窗口范围。
- 尽量使用并行来加速处理窗口函数的计算,利用多核或分布式系统来提高效率。
总结
窗口函数的应用十分广泛,可以帮助我们更加灵活的处理数据、分析数据。在具体的场景中,还需要考虑一些优化技巧,提高查询效率。
参考














